Siento las últimas semanas de silencio, pero he estado ocupado y tengo otros proyectos en marcha. Por eso precisamente quería acabar con un proyecto en el que llevo trabajando varios meses.
He decidido por tanto publicar una versión provisional del texto, con la esperanza de que será útil en los próximos meses, cuando no podré actualizarlo tan frecuentemente como querría:
- Anuncio e introducción a la serie de libros (inglés).
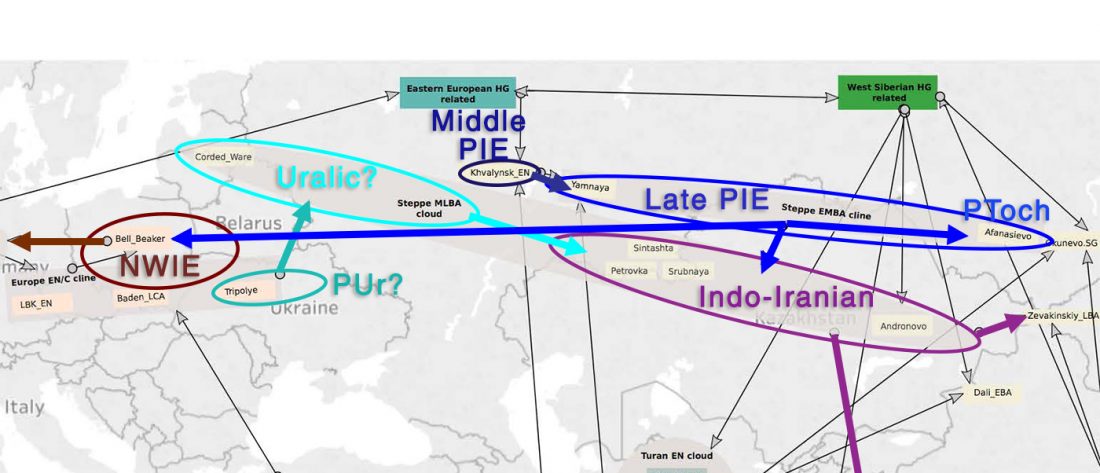
- Libro Primero: Canción de ovejas y caballos: eurafrasia nostratica, eurasia indouralica (inglés). Idiomas.
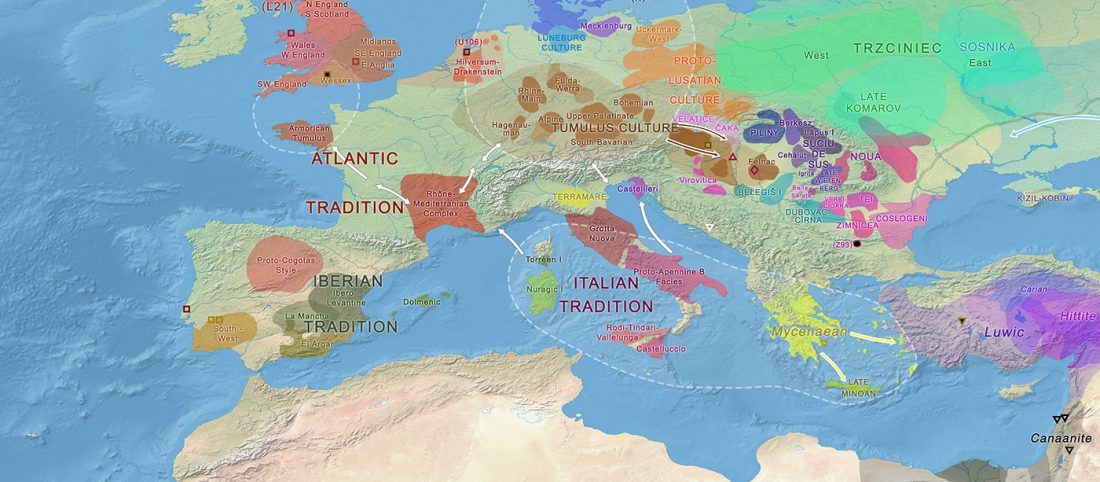
- Libros Segundo y Tercero: Juego de Clanes: collectores venatoresque, agricolae pastoresque & Choque de